Today, network performance monitoring typically relies on probe devices to perform active tests and/or observe network traffic in order to try and infer performance. This article demonstrates that hosts already track network performance and that exporting host-based network performance information provides an attractive alternative to complex and expensive in-network approaches.
The open source Host sFlow agent already makes use of Berkeley Packet Filter (BPF) capability on Linux to efficiently sample packets and provide visibility into traffic flows. Adding support for the tcp_diag kernel module allows the detailed performance metrics maintained in the Linux TCP stack to be attached to each sampled TCP packet.
Combining performance data and packet headers delivers a telemetry stream that is far more useful than either measurement on its own. There are hundreds of attributes and billions of values that can be decoded from the packet header resulting in a virtually infinite number of permutations that combine with the network performance data.
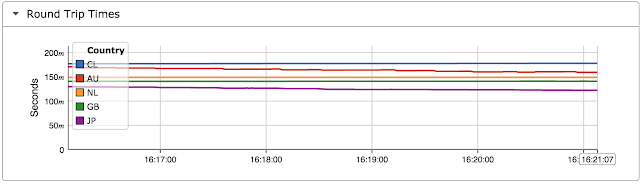
For example, the chart at the top of this article uses sFlow-RT real-time analytics software to combine telemetry from multiple hosts and generate an up to the second view of network performance, plotting round trip time by Country.
This solution leverages the TCP/IP stack to turn every host and its clients (desktops, laptops, tablets, smartphones, IoT devices, etc.) into a network performance monitoring probe - continuously streaming telemetry gathered from normal network activity.
A host-based approach to network performance monitoring is well suited to public cloud deployments, where lack of access to the physical network resources challenges in-network approaches to monitoring.
More generally, each network, host and application entity maintains state as part of its normal operation (for example, the TCP metrics in the host). However, the information is incomplete and of limited value when it is stranded within each device. The sFlow standard specifies a unified data model and efficient transport that allows each element to stream measurements and related meta-data to analytics software where the information is combined to provide a comprehensive view of performance.
# tcpdump -ni eth0 tcpThe host TCP/IP stack continuously measured round trip time and estimates available bandwidth for each active connection as part of its normal operation. The tcpdump output shown above highlights timestamp information that is exchanged in TCP packets to provide the accurate round trip time measurements needed for reliable high speed data transfer.
11:29:28.949783 IP 10.0.0.162.ssh > 10.0.0.70.56174: Flags [P.], seq 1424968:1425312, ack 1081, win 218, options [nop,nop,TS val 2823262261 ecr 2337599335], length 344
11:29:28.950393 IP 10.0.0.70.56174 > 10.0.0.162.ssh: Flags [.], ack 1425312, win 4085, options [nop,nop,TS val 2337599335 ecr 2823262261], length 0
The open source Host sFlow agent already makes use of Berkeley Packet Filter (BPF) capability on Linux to efficiently sample packets and provide visibility into traffic flows. Adding support for the tcp_diag kernel module allows the detailed performance metrics maintained in the Linux TCP stack to be attached to each sampled TCP packet.
enum packet_direction {
unknown = 0,
received = 1,
sent = 2
}
/* TCP connection state */
/* Based on Linux struct tcp_info */
/* opaque = flow_data; enterprise=0; format=2209 */
struct extended_tcp_info {
packet_direction dir; /* Sampled packet direction */
unsigned int snd_mss; /* Cached effective mss, not including SACKS */
unsigned int rcv_mss; /* Max. recv. segment size */
unsigned int unacked; /* Packets which are "in flight" */
unsigned int lost; /* Lost packets */
unsigned int retrans; /* Retransmitted packets */
unsigned int pmtu; /* Last pmtu seen by socket */
unsigned int rtt; /* smoothed RTT (microseconds) */
unsigned int rttvar; /* RTT variance (microseconds) */
unsigned int snd_cwnd; /* Sending congestion window */
unsigned int reordering; /* Reordering */
unsigned int min_rtt; /* Minimum RTT (microseconds) */
}The sFlow telemetry protocol is extensible, and the above structure was added to transport network performance metrics along with the sampled TCP packet.startSample ----------------------The sflowtool output shown above provides an example. The tcp_info values are highlighted.
sampleType_tag 0:1
sampleType FLOWSAMPLE
sampleSequenceNo 153026
sourceId 0:2
meanSkipCount 10
samplePool 1530260
dropEvents 0
inputPort 1073741823
outputPort 2
flowBlock_tag 0:2209
tcpinfo_direction sent
tcpinfo_send_mss 1448
tcpinfo_receive_mss 536
tcpinfo_unacked_pkts 0
tcpinfo_lost_pkts 0
tcpinfo_retrans_pkts 0
tcpinfo_path_mtu 1500
tcpinfo_rtt_uS 773
tcpinfo_rtt_uS_var 137
tcpinfo_send_congestion_win 10
tcpinfo_reordering 3
tcpinfo_rtt_uS_min 0
flowBlock_tag 0:1
flowSampleType HEADER
headerProtocol 1
sampledPacketSize 84
strippedBytes 4
headerLen 66
headerBytes 08-00-27-09-5C-F7-08-00-27-B8-32-6D-08-00-45-C0-00-34-60-79-40-00-01-06-03-7E-0A-00-00-88-0A-00-00-86-84-47-00-B3-50-6C-E7-E7-D8-49-29-17-80-10-00-ED-15-34-00-00-01-01-08-0A-18-09-85-3A-23-8C-C6-61
dstMAC 080027095cf7
srcMAC 080027b8326d
IPSize 66
ip.tot_len 52
srcIP 10.0.0.136
dstIP 10.0.0.134
IPProtocol 6
IPTOS 192
IPTTL 1
IPID 31072
TCPSrcPort 33863
TCPDstPort 179
TCPFlags 16
endSample ----------------------
Combining performance data and packet headers delivers a telemetry stream that is far more useful than either measurement on its own. There are hundreds of attributes and billions of values that can be decoded from the packet header resulting in a virtually infinite number of permutations that combine with the network performance data.
For example, the chart at the top of this article uses sFlow-RT real-time analytics software to combine telemetry from multiple hosts and generate an up to the second view of network performance, plotting round trip time by Country.
This solution leverages the TCP/IP stack to turn every host and its clients (desktops, laptops, tablets, smartphones, IoT devices, etc.) into a network performance monitoring probe - continuously streaming telemetry gathered from normal network activity.
A host-based approach to network performance monitoring is well suited to public cloud deployments, where lack of access to the physical network resources challenges in-network approaches to monitoring.
More generally, each network, host and application entity maintains state as part of its normal operation (for example, the TCP metrics in the host). However, the information is incomplete and of limited value when it is stranded within each device. The sFlow standard specifies a unified data model and efficient transport that allows each element to stream measurements and related meta-data to analytics software where the information is combined to provide a comprehensive view of performance.













































